Industory Expert Trainers
LIVE Project

1,500+ Hiring Partners
Affordable Fees


The fastest-growing sectors of the IT industry today are big data and Hadoop. So start enrolling yourself in the Big Data Hadoop Training in Bangalore immediately to improve your employment prospects.
What is Hadoop?
Huge volumes of data can be stored using open-source Hadoop technology, which allows software clusters to run applications. We can perform an infinite number of processes or tasks because of the vast data storage, strong processing, and computational skills. The main objective of Hadoop is to promote the growth of big data technologies that support advanced analytics, such as predictive analytics, machine learning (ML), and data mining.
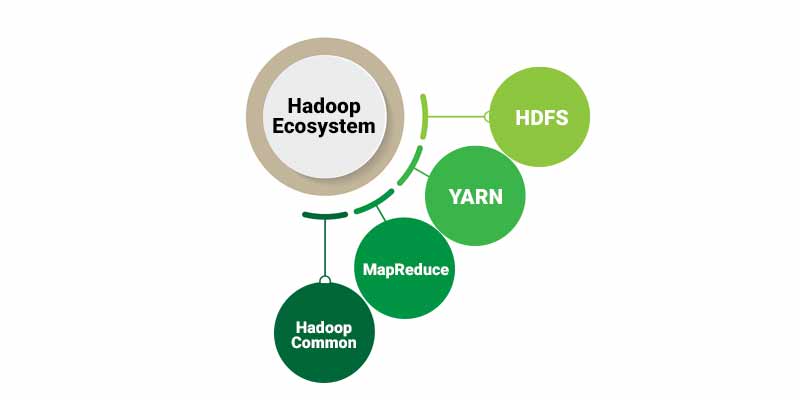
Hadoop Ecosystem
The Hadoop ecosystem is a platform or framework that assists in resolving large data problems. It has a number of components and services, such as those for ingesting, storing, analysing, and preserving large amounts of data. The four fundamental components of the framework are supported by the majority of the services in the Hadoop ecosystem, which are as follows.
- HDFS
- YARN
- MapReduce
- Hadoop Common
The Hadoop ecosystem consists of Apache Open Source projects as well as many different commercial tools and solutions. Some of the well-known open-source examples include Spark, Hive, Pig, Sqoop, and Oozie. The core components are explained below for your reference.
HDFS (Hadoop Distributed File System)
The core of the Hadoop ecosystem is the Distributed File System or HDFS. With the use of this technology, you may distribute the storage of massive amounts of data among a number of machines. This suggests that your system will view all of your hard drives as a single massive cluster. Additionally, it maintains redundant data copies. Even if one of your PCs suddenly caught on fire or experienced some technical difficulties, you wouldn’t even know anything had happened. By creating a backup from a duplicate of the data, it has automatically saved, HDFS may therefore recover from that.
YARN (Yet Another Resource Negotiator)
The Hadoop ecosystem eventually proceeds onto the Yet Another Resource Negotiator. It serves as the hub for Hadoop’s data processing. YARN is the name of the system that manages the resources on your computing cluster. It is the one who decides who gets to do the job and when, as well as which nodes are available for further work and which ones are not. As a result, it keeps your cluster beating like Hadoop’s heart.
MapReduce
An exciting application that can be built on top of YARN is MapReduce. MapReduce, the second component of the Hadoop ecosystem, is a programming model enabling data processing across an entire cluster. Mappers and Reducers, which are numerous scripts or functions you might create when developing a MapReduce programme, make up the majority of it. While Mappers can effectively modify your data in parallel throughout your computing cluster, Reducers are responsible for collecting your data. Although MapReduce appears to be a simple concept, it is highly adaptable. Complex problems can be resolved by combining Mappers and Reducers.
Hadoop Common
Hadoop Common or Hadoop Core refers to the collection of common software and libraries that support other modules of Hadoop. It is a vital part or module of the Apache Hadoop Framework, along with Hadoop YARN, HDFS (Hadoop Distributed File System) and Hadoop MapReduce. Join the Hadoop Training in Bangalore to thoroughly understand numerous Hadoop components in addition to the main Hadoop core components. Consider joining the Big Data Courses in Bangalore to learn more about other Hadoop components.
Key Features of Hadoop
Open Source
Since Hadoop is open-source, everyone has access to its source code. We can modify the source code to suit the demands of our firm. Even proprietary versions of Hadoop are available from businesses like Cloudera and Hortonworks.
Low Latency Rate
Low latency refers to processing data with little to no delay, whereas throughput refers to the amount of work completed in the given amount of time. Since Hadoop is built on the concepts of distributed storage and parallel processing, the processing is done concurrently on each block of data and independently of one another. Code is also sent to the cluster’s data rather than the data itself. These two make it possible to have both high throughput and low latency.
Cost Effective
Hadoop is open-source and leverages inexpensive commodity technology, offering a cost-effective alternative to traditional relational databases that require expensive gear and high-end CPUs to manage Big Data. Businesses have started deleting raw data, which might not be ideal for their operations because maintaining a huge amount of data in standard relational databases is not cost-effective. Hadoop provides us with two significant cost-saving benefits: first, it is open-source, which means using it is free; and second, it makes use of affordable commodity hardware.
Compatibility
Hadoop’s processing engine is known as Map Reduce, while its storage layer is referred to as HDFS. However, it is not a requirement that Map Reduce be used as the default Processing Engine. New processing frameworks like Apache Flink and Apache Spark leverage uses HDFS as a storage system. Depending on our requirements, we can change Apache Tez or Apache Spark as the execution engine in Hive. Apache HBase uses a NoSQL columnar database with HDFS as its storage layer.
Data Locality
The core principle of Hadoop is to move the code, not the data. Data locality in Hadoop refers to the process by which duties are shifted to the data to be handled rather than the code. As we deal with data at the peta byte level, transporting data across networks becomes difficult and expensive, therefore, data localization ensures that data movement in the cluster is kept to a minimum.
Performance
In older systems like RDBMS, data is handled in a sequential manner. On the other hand, Hadoop begins processing every block at once, allowing for parallel processing. Due to parallel processing techniques, Hadoop performs substantially better than legacy systems like RDBMS.
Scalability
Hadoop is a highly scalable system that makes use of a machine cluster. We may increase the number of nodes in our cluster as necessary without experiencing any downtime. Vertical scaling involves increasing hardware by doubling the hard drive and RAM, whereas horizontal scaling involves adding more machines to the cluster in this manner.
Speed
The Hadoop framework uses the Hadoop Distributed File System to handle its storage. The Distributed File System divides a large file into smaller file blocks and distributes them among the nodes of the Hadoop cluster (DFS). Hadoop performs better and is quicker than conventional database management systems because so many file blocks are handled in parallel. When dealing with enormous amounts of unstructured data, speed is essential, and Hadoop makes it easier to retrieve TBs of data in a short span.
The Big Data Courses in Bangalore offered by FITA Academy will help you learn more features and components of Hadoop as well as Big Data. This will add to your advantage for unlocking numerous job opportunities worldwide. Build a strong IT career by choosing FITA Academy!

Chennai

Bangalore

Coimbatore