Industory Expert Trainers
LIVE Project

1,500+ Hiring Partners
Affordable Fees


Big Data and Hadoop are the booming sectors of today’s IT industry. So start enrolling in the Big Data Hadoop Training in Chennai without delay to increase your job opportunities.
What is Hadoop?
Hadoop is an open-source technology for running software clusters with applications and storing enormous volumes of data. Due to our extensive data storage, powerful processing, and computational capabilities, we can handle an endless number of operations or jobs. Its major purpose is to encourage the development of big data technologies that support advanced analytics like predictive analytics, machine learning (ML), and data mining.
Demand for Hadoop
Below is a bar graph based on the results of recent research by Forbes on demand for Big Data in various industries.
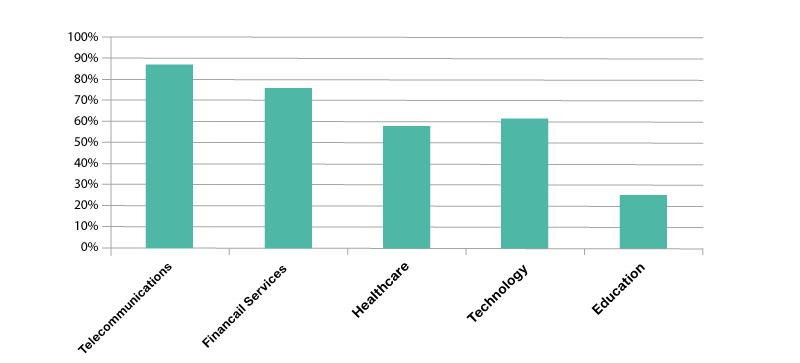
The requirement for systems that were virtually faultless in their operation evolved as the size of the global web expanded and the amount of information that needed to be processed increased, which is now known as Big Data. A lot of data needed to be processed, parsed, saved, and retrieved, but hardware systems that could handle this volume of data hadn’t yet been developed. In any case, one system wouldn’t have been adequate to hold the various types of data that the globe was consistently producing.
Key Features of Hadoop
Open Source
Hadoop is an open-source, meaning that anyone can access its source code. According to the needs of our business, we can adjust the source code. Hadoop is even accessible in proprietary forms from companies like Cloudera and Hortonworks.
Scalable
Hadoop utilises a machine cluster, and it is highly scalable. We may expand our cluster’s size without downtime by adding new nodes as needed. Horizontal scaling is adding new machines to the cluster in this way, whereas vertical scaling is increasing hardware, such as by doubling the hard drive and RAM.
Speed
Hadoop framework uses HDFS (Hadoop Distributed File System) to manage its storage. A huge file is divided into smaller file blocks and distributed among the Hadoop cluster’s nodes using the Distributed File System (DFS). Because so many file blocks are handled in parallel, Hadoop is faster than traditional database management systems and offers higher performance. Speed is crucial when working with massive amounts of unstructured data, and Hadoop makes it simple to retrieve TBs of data in only a few minutes.
Fault-Tolerant
The most important aspect of Hadoop is fault tolerance. Every block in HDFS has a replication factor of 3 by default. HDFS makes two additional copies of each data block and stores them in various parts of the cluster. We have two more copies of the same block in case one is lost due to a malfunctioning machine. Hadoop achieves fault tolerance in this way.
Schema Independent
Hadoop can handle a variety of data formats. It is adaptable enough to store data in various formats and can process both organised and unstructured data.
Low Latency Rate
Throughput is the quantity of work completed in a given length of time, while low latency is the processing of data with little to no delay. Processing is carried out concurrently on each block of data and independently of one another because Hadoop is founded on distributed storage and parallel processing principles. Additionally, code is transferred to data in the cluster rather than the data itself. Low Latency and High throughput are facilitated by these two.
Performance
Data is processed sequentially in legacy systems like RDBMS. However, Hadoop starts processing all the blocks simultaneously, enabling parallel processing. The performance of Hadoop is significantly higher than that of Legacy systems like RDBMS, owing to parallel processing techniques.
Data Locality
Moving the code, not the data, is the guiding idea of Hadoop. Data Locality in Hadoop refers to the method through which tasks, rather than code, are moved to the data to handle it. Data localization guarantees that data movement in the cluster is kept to a minimum because moving data across networks becomes challenging and expensive as we deal with data at the petabyte level.
Share Nothing Architecture
The Hadoop cluster’s nodes are independent of one another. This architecture, known as Share Nothing Architecture, prevents them from sharing resources or storage. As each node functions independently, there is no single point of failure in the cluster. Therefore if one node fails, the cluster as a whole won’t be affected.
Cost Effective
Unlike traditional relational databases, which need expensive hardware and high-end CPUs to handle Big Data, Hadoop is open-source and uses affordable commodity technology, providing a cost-efficient solution. Because holding a large number of data in typical relational databases is not cost-effective, businesses have begun to delete raw data, which may not be in the best interests of their operations. Hadoop offers us two key cost-saving advantages – first, it is open-source, which means it is free to use; second, it leverages cheap commodity hardware.
Compatibility
The storage layer of Hadoop is called HDFS, while the processing engine is called Map Reduce. There isn’t a hard-and-fast requirement, though, that Map Reduce must be the default Processing Engine. HDFS is used as a storage system by new processing frameworks like Apache Spark and Apache Flink. Based on our needs, we can switch the execution engine in Hive to either Apache Tez or Apache Spark. The storage layer of Apache HBase is a NoSQL columnar database that leverages HDFS.
Multiple Languages
Hadoop offers extended support for languages like Python, Ruby, Perl, and Groovy despite being primarily built in Java.
Enrol on the Big Data Hadoop Training in Chennai at FITA Academy to gain a comprehensive knowledge of the Hadoop framework and ecosystem for effective integration and analysis of huge volume datasets. Through this course, we ultimately help you unlock the doors of numerous job opportunities worldwide.

Chennai

Bangalore

Coimbatore